



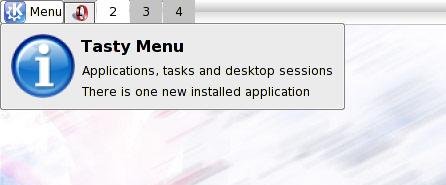
The common complaint about every desktop (with every=(Gnome||KDE)) is that it’s difficult to spot where the recent installed applications, maybe now it’s finally over: Tasty Menu will notificate into its tooltip how many application have been installed and the menu will highlight the categories where the icons of the new aplications are. It’s still not perfect, unstable and heavy, but it’s starting working.
So when someboy else complains about this, he will be punished with 5 uninterrupted hours of Magical Trevor 🙂
Tag Archives: linux
Tasty Menu 0.3
Again another release of Tasty Menu.
It is slowly getting shape, my TODO list is shrinking more and more.
Summarizing a rough changelog:
0.3:
-Keyboard navigation
-Right-most list doesn’t open groups on mouse over
-More evident focus on lists
-Added a left mouse button menu
-Menu size configurable
-A more clear highlight of the currently opened submenu
-Simple integration with Kerry Beagle
-Added a big tooltip like other kicker applets (no it isn’t the cool tooltip of kicker, because at the moment it isn’t usable by 3rd party applets unless big and ugly code duplication)
-It’s possible to override the global shortcut Alt+F1 to make it open Tasty Menu instead of KMenu (default disabled)
-Uses KconfigXT
-The menu button text label can be disabled
Of course you can download it from here
Tasty Menu 0.2
Uploaded Tasty Menu 0.2: this version has a more usable and a little bit less unfinished aspect, the most prominents highlights are:
-Fixed some crashes at exit of kicker
-Now the behaviour it’s similar to the one of a normal popup menu so it’s now possible to launch an application with one single mouse click
-Configurable size of icons
-Listviews with a more compact look in order to waste less space
-Kicker button it’s a little bit less wide
-Kicker button icon grows with kicker
-Some informative tooltips
-Reverse Layout support restored again
-Beginning of an help page
Available here.
Tasty Menu: what do you wanna eat today?

Today I just released for the joy of everybody a first very dirty work in progress of my new pet Tasty Menu, if you dare, you cat download it here, but of course don’t complain if your kicker becomes a great ball of fire :-).
And now some introductory blah blah on it.
I found unconfortable the current KMenu due to the plethora of menu entries and started to think about how that menu should be…
looking around the various approaches I tried to take here and there the saner ideas of the various menus around there.
The Windows xp menu is hated by almost everyone I know, Yeah, I know it isn’t very objective, but it’s the impression I have. I think the reason is that the prominent icons on the left are the automatically generated most used apps list, that is out of the user’s control and the second reason the list of all programs is very hidden on a submenu.
The menu in the new Novell desktop is very similar, but I think it should be a little bit better, because if I understood correctly the default list on the most prominent place is a list of the favourite apps that is the user to decide.
the list of all the available apps it’s on a separate window, that renders the process of searching for an app much slower, but at some extents easier, because a big window makes the categorizing more clear and the icons looks a little bit less cluttered. A similar thing applies to OSX, where the apps are browsed through the file manager. Similar thing applies to Gimmie(http://beatnik.infogami.com/Gimmie) where the launcher of “objects” is a window. Speaking of Gimmie is very interesting how they have integrated also other infos (Documents, contacts and other stuffs) in the same app.
A strange thing about the default Gnome menus: at a first glance separing apps and other actions like logout seems cute, but they seems to fail in real world where new users seems confused by the two/three menus instead of one (I have also failed on it: the first time i tried Gnome 2.x I always opened the wrong menu in order to find the logout button :-P) I think it will definitely need more testing.
So I started hacking around this little applet in the hope of finding something valid, that i surely don’t pretend to be perfect, but at least to be a testbed where new concepts could be rougly drawn.
The left part of the menu is very similar to the Novell idea: you have a search box that is always selected when the menu is opened (the search result are displayed in the leftmost listview), followed by a combobox that decides what the following listview: favourite applications (default), most used applications, recently used applications and recent documents.
The right part contains the whole kmenu and takes the aspect from KBFX, the middle column contains the top level categorization (plus in the current kmenu arrangment there are also the control center, home folder and find files, but i think there should be present only categories). in the left-most listview there is the content of the category currently selected in the middle column. I think in this way even if it has the same number of items it _appears_ less huge than with a popup menu/submenu structure.
every items have two row, for the name and for the description, in order to make a more it more informative. On each selected item appears an action icon on the right, at the moment they are “add bookmark” on application icons and “remove bookmark” on favourite apps list.
The bottom buttons are the usual switch user, lock session and logout. In a first time I didn’t want to put them, I tought that these function should be delegate to another applet like that session applet , but as I said, it seems that the multiple menus concept it’s a thing that doesn’t work very well in practice.
The left-most btton contains the user name and icon, and clicking on it it opens the kcm used to edit the user’s profile. I know it seems silly, but I read on some usability report somewhere that in the tests with the XP start menu when asked to edit their profiles many users clicked on the user icon in the menu and were disappointed that nothing happened. Maybe I should integrate that button with the Switch user one.
At the moment there is still an huge room for improvement, it’s still not very stable and it still lacke some important features thet I still hadn’t figured out how to implement them, in particular:
-a global shortcut and keyboard navigation,
-tooltips to truncated menu entries and actions,
-the ability to launch an app with only one mouse click like the normal menu items,
-the ability to make it a normal window,
-drag ‘n drop support in the management of favourite apps,
-and of course making it more friendly with smaller screen resolutions, at the moment is really huge 🙂 (that is not necessary a bad thing)
Polyester bugfix
Released today a new bugfix version of polyester that fixes the annoying issue of 0.9.2 about tabbar label colouring and also have some other micro-fixes or enhancement.
Go get it 🙂
What I’m working on
 Its name is Tasty Menu and is a KMenu replacement (oh,no! another one! yah, another one :P).
Its name is Tasty Menu and is a KMenu replacement (oh,no! another one! yah, another one :P).
It’s aim it’s to be a testbed on usability issues rather than eyecandy.
How it will look like? See on the left.
The layout will have three colums (more width than height, shoul look ok also in lower resolutions).
The column on the left (the more accessible onr) will be for most used applications and for the results of the search field, the second column has the main categories and the column on the right contains the items of each category. It’s still too alpha for being released, but I feel it already more confortable than standard kmenu.
Stay tuned for more details and a first release!
Glaze update
I just released Glaze 0.4.6 KDE iconset, only few more icons i drawn in sooo many months, and probably the last update for many months again.
It’s only that now I’m a little bit bored of drawing icons, because making so much little pictures can be really mind-hurting 😛
Polyester 0.9.2
Polyester 0.9
Today I’ve released a new version of the Polyester kde theme. This time it has both many bugfixes and some new nice enhancements, in particular I’m very proud of the new kick-ass listview.
Hoping I didn’t introduced too many new bugs, this will be the last release from here to some time in the future, next version after the exams session 🙂
As usual you can find the tarball on this site and also on Kde-Look along some precompiled binaries.
PHP, cms, wikis and Web 2.0, and ONE to rule ’em all
As I promised here it is a long and grammatically wrong rant about what I think about the status of PHP and of the web application in general, starting from the tools I used for my thesis (PHP5, PostgreSQL), through a brief description of some today php cms and wikis and ending considering what i think it’s still missing.
PHP5 rocks
Since that beastie will run on a dedicated server there was no need to support the crappy hosting services with only PHP4/MySql4 service. With PHP5 it is possible to use true object oriented probramming without being deadly slow and using all that must-have things like public/private, inheritance and polymorphism, so you can shut up all that annoying Java programmers when they laugh at you :-P. Unfortunately, I’m absolutely sure that web hosting services won’t offer PHP5 service until 2050 or so, partly because a big slice of PHP programs are written so badly that they pitifully fails to run under PHP5.
PostgreSQL rocks too
The system had to support complex hierarchies (simple restrictions-free ontologies, like RDF, I leave owl-like restrictions to my heirs :)); Implementing hierarchies whit that crappy db engine that begins with “M” that does not support triggers and the default engine doesn’t even have foreign keys, Au contraire PostgreSQL it’s almost perfect, so as the other best things nobody cares of it and everybody goes with the cool and trendy MySql, being forced to move all of the integrity checks into the PHP code. Maybe I will give to Mysql a second opportunity with the promising version 5, but I still haven’t tried it.
PhpWet sucks
My poor cms that runs this site sucks badly. I realized that when I had to migrate the site from www.fosk.it to www.notmart.org. Changing some pathnames and adding some sections was very painfully, and anyway: what I was smoking when I decided to write my own broken themplate engine when so cool template engines exists already?.
But anyway it is still the only cms I can use without going mad because 1) every system has his very own idiosyncrasies an I know the mines, but 2) more objectively is the only one that supports all of some things that I consider irrenunciable. In particular:
- all articles must go in a well ordered hierarchy (sorry, but I think everything too much in hierarchies :), I will explain why)
- multilingual support (translate also the articles, non only the interface)
- and last it must be easy to add more complex objects as article types, for example not only articles with title and content, but things with more fields that are required for other applications (for example photo, description, price and quantity available for an item in an e-shop site).
And what about other cms, wiki and journals?
Every cms I’ve tried fails something and excels some other things (or wikis, or journals, it doesn’t matter: that distinction should be made for the final website, not for the engine, otherwise it only justifies a lack of flexibility), in particular:
- WordPress
- Only a journal, the world is not a blog and even if it can run some other kinds of websites and it is getting better it is still not ready, but probably it will be able to handle more generic content in the near future.
- Mambo
- After trying it for a job that it has not been done, I realized I hate it, because it’s complex, it produces crappy HTML, supports translations only with a third-party add-on, his administration panel uses an ugly javascript menubar and it is difficult to exit from the “list of latest news” scheme and doing a more ordered hierarchy (oh no! again with that obsession :))
- Drupal
- This big beast is rather interesting and definitely I will learn more about it. Reassuming roughly the things I like about it, here it is:
- The HTML it produces is fairly better than the Mambo one.
- It supports a nice taxonomy, but I think the nodes should have been forced to be always comprehensible names instead of numerical ids that can be renamed later as strings (i.e. nobody will ever do it:).
- It uses clean URIS with a good use of Apache mod-rewrite: www.mysite.org/category/subcategory is fairly nice than www.mysite.org/index.php?id=261765&action=edit&foo=bar&bah=antani :-). The first one is easier to read to both humans and search engines
There surely are also something I don’t like, in particular translations support as Mambo is done only with a third party add-on that I truly would like having it included in the official version. Moreover, I believe that the database structure could have been fairly simpler, I still haven’t studied the internals well, but that 55 tables madness sounds me strange.
- CMS made simple
- This, as his name suggests, is fairly more simpler and young than the previous two, but I think it’s one of the more promising. It’s a no-nonsense cms that supports articles ordered into a simple hierarchy (yeah :)), news (with rss, as all the others) and a simple search function. There are some things I would see in a future version and I would absolutely love it:
- Maybe the news should be also articles in the hierarchy.
- Translation of the content of course.
- Ability to add more richer content (like the example of the e-commerce before, but it could be some other thing)
- Mediawiki
- And now His Majesty Mediawiki, that runs Wikipedia, my daily drug :). This being a wiki is a very differend kind of beast respect the previous ones. Even if I don’t know it very well (and I will surely remedy that) Let’s see some of the peculiarities that made me reflect a lot:
- Track changes: Due to its open (in the sense everybody can modify the content) nature every change made can be easily rolled back and an history of all changes is always accessible.
- Heavily based on search: this is mandatory if you have millions of entries like Wikipedia, but the latest version has a comfortable way to edit the sidebar with the pseudopage MediaWiki:Sidebar
- The articles are stored and edited in an own simple language rather than HTML. In this way they are easily edited in a faster way than HTML and it’s theoretically simpler to translate in other languages than HTML or future newer versions of HTML (the day it will be possible to download auto generated pdfs from wikipedia articles I will be the happier child in the world:)
- the relations/hierarchies between articles (think about the taxonomy of the plants or animals in Wikipedia) are computed from the article content rather from esplicitly specified table fields. This leads to a more flexible and fast way to categorize the articles. In order to avoid performance problems the article structure must be parsed at publishing time and the relations must be put in the database anyway.
Web 2.0? Does a Web 1.0 ever existed?
Today there isn’t a buzzword so buzz how “Web 2.0” is. But it’s still a very vaporous concept. To me even a “web 1.0” still not exists, because we are still in a 0.someting era, an immediate post “this site is optimized for internet explorer at 800×600 resolution”. At the moment there isn’t yet a clear agreement how the web should look like in the future. Somebody has even tried to make a validator that checks if your site is web2.0 compliant, but IMO it has some serious problems. First, it binds himself too much with the concept of the blog “ex.Has a Blogline blogroll?”, but altough the blogs became an important part of the internet they are not and will not be the internet. It also attempts to bind on a specify language (“Appears to be built using Ruby on Rails?”), and the strength of the internet since its creation has always been its platform Independence (even with the various hijack attempts of Microsoft).
The leading group is the Semantic Web, part of the W3c that works on some things very interesting with the constant risk being too much academic (with academic <=> useless and complex). The work that started it all was RDF, that is a simple and very generic XML schema for representing subject predicate object constructs. It’s not meant to be used alone but with RDF dictionaries ad so it become rss, owl and many others. So rss has many incompatible variants because RDF is very generic.
So how is the perfect website?
After all why managing well hierarchies is so important?
Yeah, I know, hierarchies are an absolutely not intuitive thing and these will probably help only few user to navigate the site (have you ever used the sitemap to navigate a site? I hadn’t), because that is the search that is becoming more and more important, because it’s easier and more natural. But I think a clean hierarchy helps the one who creates the site to make a more organic work, but that’s not the most important thing. If a hierarchy (or better: an ontology, that is in veery poor words a collection of objects and relations between object) is exported in a clear and formal language like OWL or some other (hopefully simpler) RDF dictionary would help some cool automated tasks, like helping the search engines to understand what the page relations are (maybe there could be some kind of relation between two pages even if there aren’t hyperlinks between them) or syndicating not only the page of news (RSS) but also the other content.
A cms? a wiki?
I think one engine should be able to manage “content” in every ways the administrator wants to display it. So an engine should be every of these things together, the final aspect/behavior is details.
How the content should be edited/stored on the server
And most important: what format should be used? HTML would be the more obvious answer, but I think the ability of download a page/article in more rich formats like pdf or opendocument is very important, and is also important to remember that HTML is not a fixed entity and will change even radically in the next few years (when somebody will support it is another discourse 🙂 ).
So in order to create a system a little more future-proof it is necessary to make the storing format on the server pluggable and some candidates pops into my mind:
- Mediawiki format: very simple even to be written by hand and I think it contains enough information to be converted into a well printable format. Probably it would be also easy to write a WYSIWYG editor for it.
- Docbook (that will be translated in HTML and other final formats by an XSLT stylesheet): very complex and expressive, but too ugly editors.
- Open document: very complex and expressive, publishing a new article would be as easy as uploading an OpenOffice file. But producing decent HTML would probably be hard and computationally expensive (it would be necessary caching everything).
And off course since HTML is not the alpha and the omega of representing information it should be possible to download the page in as many different format as possible. You want an HTML page? www.notmart.org/foo/bar.html. You want a PDF file? www.notmart.org/foo/bar.pdf and so on.
How the user should publish content
This should be an easy procedure for everybody, even the most computer-illiterated and of course it should be totally platform independent.
It would be nice having both possibilities to edit the site content both with a normal web browser or a specified client: think about XML-RPC and the flock blogging interface, but something of course not only limited to blogging. Obviously the ad-hoc client won’t be the only way to edit content, in order to maintain total platform Independence a web based interface should be always available (and of course somebody will hate the graphical client and some others will hate the web interface too, so the choice must be always present)
If i would like AJAX or not for the web based interface i am not sure: some things like Google Maps are cool but try to use them with a 56k modem or with an old web browser :-). So if advanced javascript, AJAX, XFORMS (when in the year 2050 some browser will support it 🙂 ) and other buzzword are being used there should be always a plain old HTML version like Gmail.
That’s it 🙂
Here are my random thoughts about the web. Maybe if some days I will have some time I will try to implement some of these ideas, but probably I won’t have time and probably tomorrow I will totally have changed my mind on this argument. In the meantime I will continue to search the perfect system that I’m sure it is somewhere out there 🙂